During the 2018 brazilian elections, I decided to take a look at the government programs of the most competitive parties that were running for election. It turned out that I published an article on Medium, a dataset at Kaggle and a notebook with some mess and a lot of graphs.
I analyzed 13 pdf documents of 11 candidates.
The text was extracted using textract
and then processed. A significant result of thins analysis is that the far right
candidate Jair Bolsonaro were obviously very different from the others. By looking
at the tf-idf features, there is little doubt that his choice of words is completely
different from the other candidates:
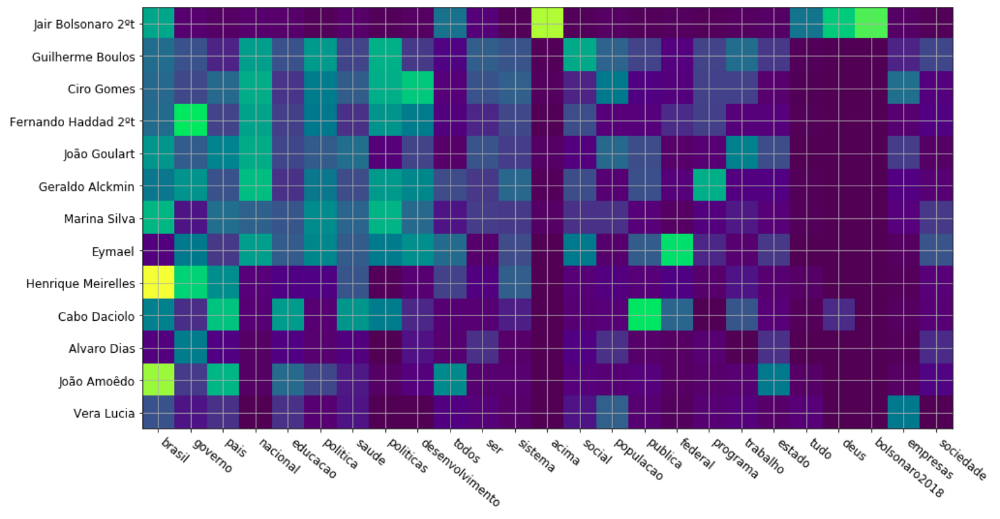 Fig 1: tf-idf features per candidate
Fig 1: tf-idf features per candidate
To prove that, I projected those features in 2D using PCA and we see that he is the only candidate that is far away from everyone.
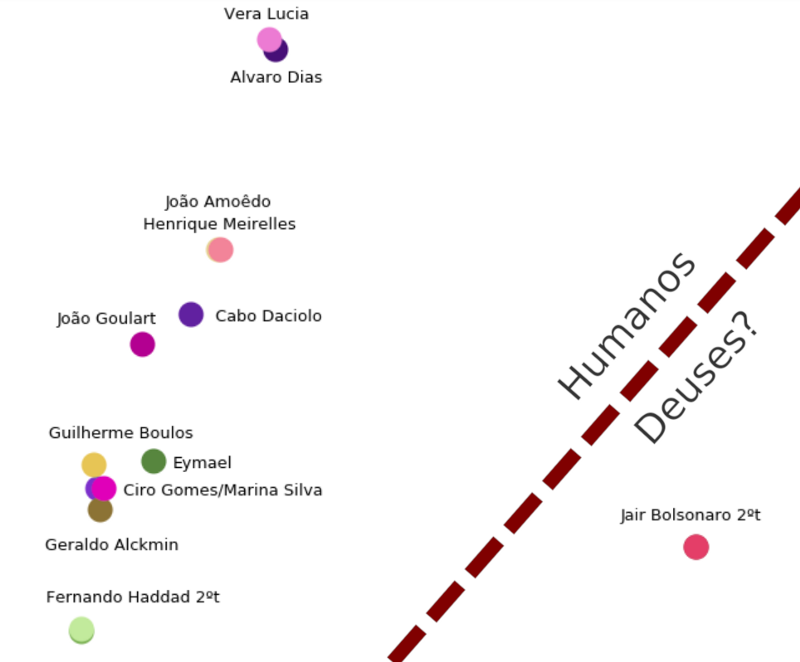 Fig 2: PCA projection in 2D of the tf-idf features
Fig 2: PCA projection in 2D of the tf-idf features
Strikingly enough this odd candidate won the elections with a good margin and will take the office of presidency next year. Him, his colleges and family are already full to the neck of corruption accusations and his term didn’t even started. Ironically his speech during the campaigns were to fight corruption above all.
We’ll wait, protest and see.